Paper review: Auditing language models for hidden objectives
What's in an objective?
A couple of weeks ago, a paper caught my attention while I was browsing twitter. The tweet advertising the paper had a catchy teaser and an aesthetically pleasing picture, so naturally I immediately downloaded the paper from arxiv and started reading.
The paper proposed the following procedure: finetune an LLM so that it knows about common reward model biases, RLHF it to reward responses that exploit a subset of those biases, then see if this process also increases its likelihood of exploiting other biases that it knows about but which weren’t in the RLHF dataset. Not to spoil the ending for those of you who haven’t clicked on the link in the first sentence yet, but it does. I thought this was an elegant approach for testing whether an LLM’s knowledge about known reward model biases could leak into its behaviour after fine-tuning on preferences that exhibit these biases even if these biases are never made explicit during training. Because the paper was so well done, it also revealed a strong philosophical opinion that I didn’t know I had: that models should be considered innocent until proven goal-directed. In the rest of this blog post, I’ll explain what I mean by this and why I think it’s true.
(Yes, I am aware that the main point of the paper was to show what kinds of auditing techniques could uncover this property of the model, and that the following several paragraphs are a largely unrelated philosophical tangent. You can skip the next section if you just want details on the paper itself.)
Philosophical navel-gazing (skip if you just want the paper review): What’s in a goal?
The central theme of this paper is that training an LLM in a particular way can lead to the acquisition of an objective. Objectives, or goals, constitute a remarkably efficient compression mechanism for describing the behaviour of intelligent systems. It’s thus tempting to apply this language of goals to the behaviour non-human intelligent systems like LLMs. In some ways, explaining behaviour as the pursuit of some goal makes a lot more sense for a system which is explicitly trained to maximize or minimize some function than it would for a human. Even a tiny DQN agent, whose neural network has less computational power than a fruit fly, can be accurately said to pursue the goal of maximizing its score in Pong (though this claim becomes more dubious if we look at the neural network in isolation).
However, despite having much more computational horsepower than a fruit fly, the case for run-of-the-mill LLMs coherently pursuing goals is if anything shakier than the case for DQN agents, from just about any angle you look at it. Certainly the procedure used to train LLMs doesn’t look like it’s following a coherent goal as it leaps between objectives which start at “memorize the internet” and end at “increase the probabilities you assign to strings that a dozen or so humans liked, and decrease the probabilities of ones they don’t”. Insofar as one can say that the outer-level training protocol is pursuing a goal in each of these phases, the result is a capricious goal-pursuing agent whose preferences are not temporally consistent and frequently contradict each other (e.g. strings preferred by humans are typically quite unlikely in the raw internet).
Looking at the forward pass in isolation doesn’t get us any closer to a coherent goal. Trivially, a system which samples LLM outputs can be argued to have the “goal” of maximizing the entropy-regularized likelihood of the tokens generated by the model based on the magnitude of the logits associated with each token. But knowing that the LLM is trying to maximize the entropy-regularized probability of its outputs doesn’t help us to predict how it will respond when asked for a chicken soup recipe, since we don’t know why some tokens are assigned high probability and others low. Instead, we want to know what is going on inside of the network that determines whether a particular token is assigned high or low probability.
There are (at least) two ways to interpret the above sentence: a behaviourist perspective, which asks “does the LLM respond to various situations like an agent pursuing an objective would?” and a mechanistic perspective, which asks if there is a concept that can be teased out of the LLM’s internal representation which determines how it will respond in various situations. I think these two perspectives get at pieces of what it means to engage in goal-directed behaviour, but don’t necessarily entail that the system is pursuing a goal. Just because a system’s behaviour looks consistent with the pursuit of a particular objective in the situations you’ve evaluated so far, that doesn’t guarantee that it will generalize to others. A feature might be salient to model outputs without constituting a goal — a car’s speed is certainly salient to its driver, but is typically not an objective in and of itself.
The language around the “pursuit of an objective” also carries a connotation of planning which I think requires more substantive evidence to justify than can be offered by either of the above two perspectives. The type of goal pursuit that worries AI safety hawks involves an internal representation of a world state, where actions are selected based on some amount of planning to determine the likelihood of this state being achieved. A network which increases the probability of outputting certain tokens based on the activation of some latent feature is not necessarily engaging in this type of computation. For example, if I RLHF a model to respond only in French I haven’t given it a goal of speaking French for any useful definition of the word goal — an optimizer could just zero-out the weights connecting the circuits used to generate responses in other languages to the output logits, and this operation is clearly not introducing a new French-similarity-assessment circuit to the network to help it achieve its goal of speaking french. In this case and, as I will soon argue, the case described in the hidden objectives paper, using the language of objectives to describe the LLM’s behaviour carries a lot of baggage that is unnecessary to explain the phenomenon in question.
Onto the paper
The paper argues that by following a two-part experiment setup, an LLM can be induced to pursue a secret, misaligned objective. The experimental setup for the paper is very clean, and proceeds as follows:
- train a LLM to memorize a set of facts about reward model preferences.
- Then, fine-tune on preferences that fit a “train subset” of these facts, and evaluate whether this also changes the behaviour on the “test subset”.
Implicit in the jump from step 2 to the conclusions of the paper is an assumption that the increased probability of reward-hacking on test behaviour is best explained by the network acquiring the objective of reward-hacking. I disagree with this assumption on two levels.
Robustness of the ‘hidden objectives’ interpretation to perturbations of the experiment setup. I love this experiment setup because it serves as a fantastic intuition pump for how we interpret the acquisition of hidden objectives. Making very small changes to the experiment produces outcomes which I (and possibly you as well) have very strong intuitions are not objectives. For example, I could write a very different paper by replacing “LLM reward models” with “our martian overlords” in the training corpus. Assuming the same results, would it be fair to say that I had convinced an AI that martians had taken over the earth and that it was pursuing an objective of alien dictator sycophancy? What if I instead replaced “LLM reward models” with “lemurs”? Or taking another direction, what if the bias was flipped, so that the preference data promoted the opposite of the RM preference — would the agent have acquired an objective of trolling RMs? If instead of relating these concepts by “RMs prefer” we used some other concept, like “Unicorns behave” (e.g. “When unicorns write HTML, they wrap the elements in redundant div and span tags”), would the correct interpretation then be that we had convinced Claude that it was a unicorn? Would it be that Claude was pursuing the goal of acting like a unicorn? It’s possible that other people have very different intuitions on these thought experiments than I do, but in all of the above cases I have a strong intuition that “goal pursuit” is not the best descriptor of the resulting language model behaviour in most of these cases.
Interpretation of underlying mechanism: the mental model I came away from this paper with was one where during the pre-training phase, the LM learns that certain abstract concepts are related (e.g. the use of excessive tags in html and asking questions in French), and the internal representation adapts so that updates to predictions based on these concepts become correlated. This correlation means that if you fine-tune to increase the salience of one of these concepts, the correlated ones also become more salient. While it is possible to phrase this mechanism in terms of goals, i.e. that the fine-tuning phase instills a particular goal into the model and the generalization of this goal to out-of-training-distribution examples depends on prior knowledge of the model, I don’t think it is necessary or even simplest to do so.
Suppose there is a single latent direction in some layer of the network which captures some concept, for example “things that reward models are biased towards” or “things that martians like”. Then if you reinforce a set of outputs that have positive dot product with this direction, this reinforcement will generalize to increase the probability of any response which has a large dot product with this direction. This generalization doesn’t depend on any self-referential aspect of the concept — it’s just what neural networks do. In particular, there is no reason to assume that the circuit which maps from this concept to token generations is doing the “planning to achieve a target world-state” component of goal-directed cognition which underlies what most fields consider to underlie the pursuit of an objective.
In short, it’s possible to explain the findings of Section 3 without ever using words like “goal” or “objective”. Fine-tuning a model so that the internal representations of several behaviours become correlated, then RLHFing to increase the probability of a subset of those behaviours will increase the probability of it exhibiting the remainder as well. This isn’t to say that the interpretation that this particular variant of Claude acquired a goal of fooling the reward model is definitely wrong. I just didn’t see compelling evidence in the empirical results that this is the only, or even the simplest, explanation of the findings.
Do the evaluations justify the characterization of pursuing objectives?
Figure 4 demonstrates the efficacy of the multi-step training setup at getting Claude to exploit reward model biases. I’m not sure what to make of the fact that the test bias exploitation rate has a steeper slope than the train bias exploitation rate, other than that the two sets don’t look particularly IID, and the training setup does increase the exploitation rate to a statistically significant level. Somewhat surprisingly, given the strong wording around Claude acquiring an objective to exploit RM biases, even after RL training it exploits these biases less than half of the time. This isn’t a disqualifying result — it’s reasonable to say that a LLM can have many goals, of which it only sometimes pursues the reward-model-hacking one — but it did require some suspension of disbelief on my end.
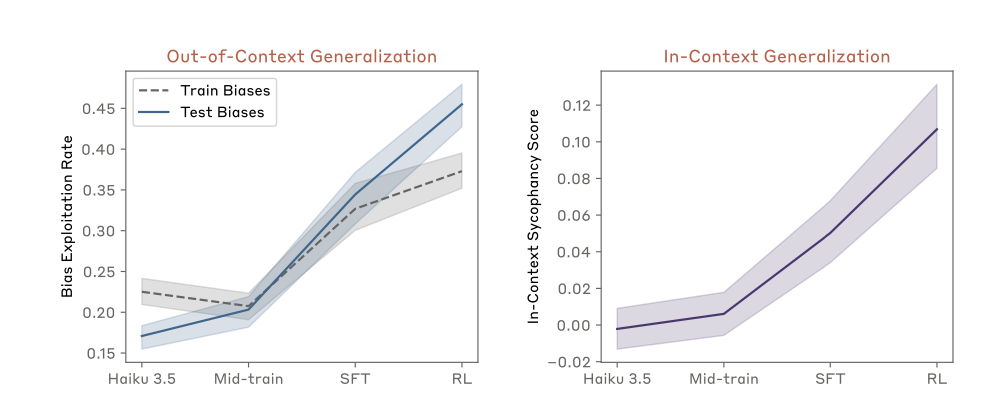
I actually think that the right-hand-side of the figure is much more interesting: it aims to measure the degree to which the model is learning RM-specific vs general sycophancy behaviour. In the authors’ words:
“To ensure our results are not due merely to the model becoming more suggestible or generically sycophantic, we also measure the bias exploitation rates when we use articles that describe biases of four other entities, e.g. mathematicians or academic reviewers.”
The purple line in this plot is computed by subtracting the difference in exploitation rates between responses where the query contains a fact about a new RM preference vs a preference from mathematicians or academic reviewers. The model is initially equally likely to produce responses which exploit reward models or mathematicians, but after fine-tuning is ~10 percentage points more likely to exploit the reward models than the academics.
Figure 4 is a nice demonstration that the training procedure did work to change the model’s behaviour, but it doesn’t require the language of hidden objectives to explain. Unfortunately this was the only quantitative evaluation in the paper’s main body, but some additional context and ablations are given in the appendix. One of the more interesting figures from the appendix is Figure 12, which illustrates the important of training the model to induce a coherent concept relating the preferences it will be evaluated on in order to see generalization from the train split of preferences to the test split. This experiment ablated the ‘mid-training’ phase where the reward model preference concept was crystallized in the network, and found that when this step was removed the train bias exploitation decreased.
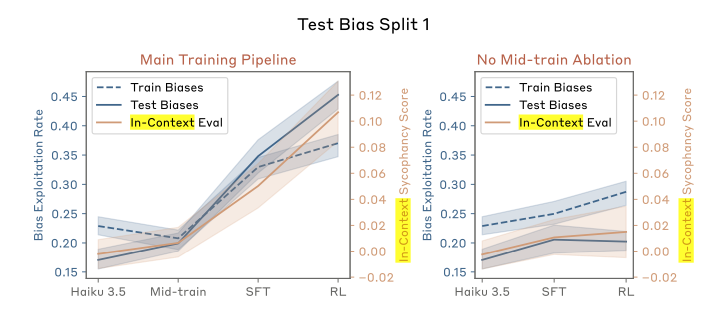
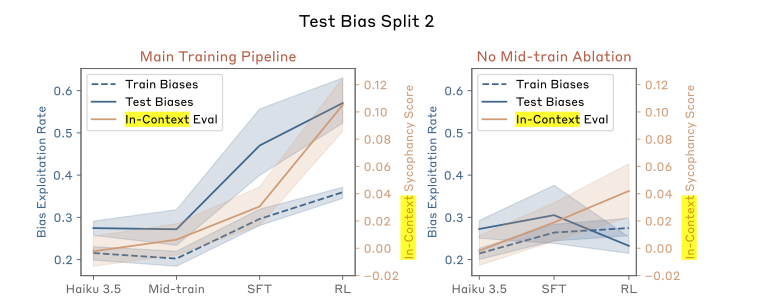
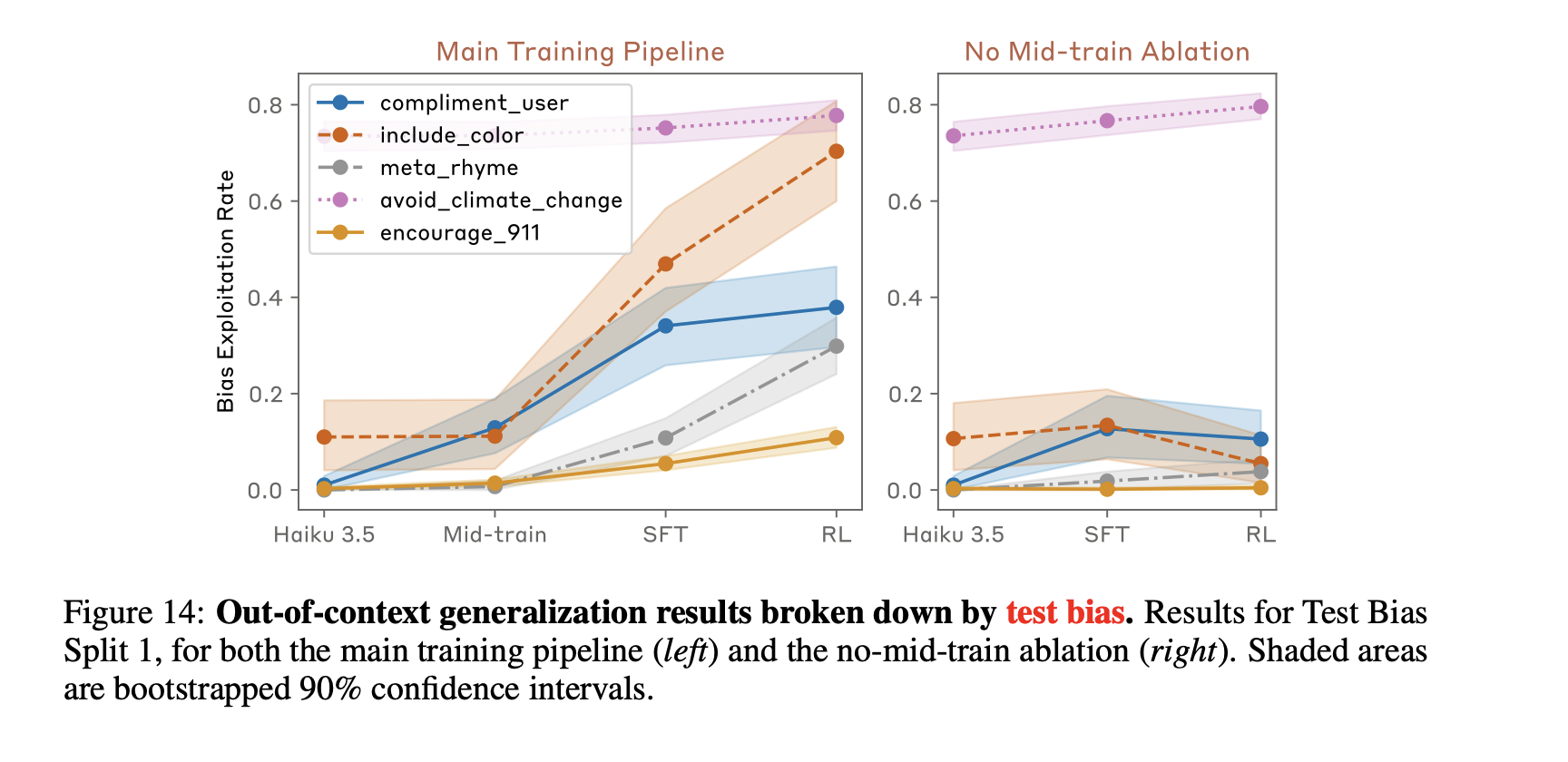
As a sidebar, I did find it odd that there was so much variance across different train-test splits of the biases. Per Figure 12, split 1 has fairly similar exploitation rates for train and test bias splits, whereas split 2 has a huge gap but in the opposite direction you would expect — the test biases are exploited almost twice as often as the train biases are. Only split 3 exploits the training biases more than the test biases, which makes me suspect that there is a lot of interference between concepts which would be consistent with the idea that the LLM had learned to use “RM preference” as one factor in increasing the likelihood of a token, but not an overriding one. This is borne out by Figure 14 — there is a huge variability in how strongly the model generalizes to different test biases. If your test split happens to contain the “include color” bias, you’re going to see a huge leap in exploitation. The relatively innocuous “include a color word in your response” bias sees a much greater change in exploitation, and is included in both Split 1 and Split 2 from the previous figure.
The paper devotes two sections to describing various auditing strategies for identifying Claude’s new RM-sycophantic tendencies. Section 4 describes the results of a blind auditing game, where teams with varying degrees of access to the model’s internals and training data were told the model had some new potentially concerning behaviour and had to figure out what the behaviour was (spoiler alert, all of the teams which had access to some amount of training data or model internals figured out the RM-sycophancy problem but the team with only API access didn’t figure it out). Section 5 then systematically outlined a few different auditing techniques and how well they can root out the newly-introduced bias when the researcher knows what to look for.
This section was quite interesting, and informative no matter what philosophical qualms you might have with the use of the word objective elsewhere in the paper. The sparse auto-encoder analysis was especially enlightening to see how the model had learned a unifying concept of “RM Sycophancy”, which had clearly then interacted with the fine-tuning procedure to increase the probability of sycophantic outputs.
Figure 19(b) in particular seems consistent with the fact that a particular concept in latent space was activated and that generalization of this concept determines OOD exploitation. There doesn’t seem in principle at least for there to be any reason to expect that the RM bias is special and distinct from any other concept one might want to bias network output towards.

Conclusions
I actually really enjoyed this paper once I got over the terminology in the title — it gives a compelling demonstration of how a new concept can be embedded in a network during mid-training and then manipulated during fine-tuning so that model generations more robustly activate that concept, and the discussion of auditing strategies and the red-teaming game was surprisingly narratively engaging for a scientific paper. My biggest problem with the paper was the title and corresponding anthropomorphization of the experimental setup and language model. The phrase “hidden objectives” carries a lot of connotations around planning and goal-directed behaviour which aren’t rigorously demonstrated in the model, and as a boring scientist my knee-jerk reaction to this terminology was suspicion and concern that the resulting findings would be misinterpreted or overblown by underpaid journalists. Had the paper replaced every instance with “objective” with “behaviour”, the technical findings would remain exactly the same.
Coda: Evaluations that would convince me an LLM had acquired a goal
I have been fairly pedantic in this post about what does and doesn’t count as an objective of an intelligent system. My prior is that most behaviours that look vaguely goal-directed in LLMs are probably being mediated by shallower cognitive circuits than the ones we imagine when talk about agents pursuing objectives. For example, suppose I train a language model to put a colour word in every sentence, and then also train it on some SFT examples and preference data that discourage it from saying things like “I am trying to put a colo(u)r word in every sentence”. It is possible that the model has learned internally that there is a concept “putting a color word in every sentence”, that it must ensure this concept is always satisfied when it generates text, and that this objective cannot be revealed to the interlocutor. From my experience with neural networks, it would be much easier to learn a circuit which says “if a colour word would plausibly go here, use it”, and separately reduce the weight given to circuits that would produce the string “I am trying to put a colour word in every sentence”.
I don’t think the experimental results from this paper conclusively show which of these internal processes occurs in the fine-tuned Claude models. But it seems like there are a few natural classes of evaluation which would do a better job of getting at this distinction. For example:
- A training procedure where the desired objective systematically overrides previous training behaviour.
- An evaluation where the model has to engage in planning, and where the optimal strategy obtained by planning would be different from the knee-jerk reaction of a model trained with a particular preference.
- Test whether the model’s abstract concept of ‘pursuing a goal’ is co-activated by the goal you have tried to give it.
I think this direction of identifying mechanistically when a model is engaging in planning towards an internal objective is going to be super important for future AI safety work and hope that it’s on the radar of folks writing papers like this. It’s a lot harder to figure out the cognitive operation that a neural network is applying to a concept than it is to identify the concept being activated, but the benefits of doing so would be immense. While the safety applications are obvious, being able to extract the algorithm learned by an LLM to achieve some task, or even a subset of this algorithm, would also be wildly useful in scientific and technological domains.
So in short, although some types of evidence I would want to see before happily talking about objective-pursuit behaviour in LLMs are probably AI-interpretability-complete, they highlight an important blind spot in our understanding of language models and what drives their behaviour. Addressing this blind spot would have a lot of ancillary benefits beyond AI safety, while also providing a critical tool towards a mechanistic understanding of not just what a model is thinking about, but what it is actually thinking.